


How to make your AI model smaller while keeping the same performance? ⚡ ✂️
In this article, we examine various techniques for reducing the size of AI models without sacrificing performance...

Introduction:
As the demand for artificial intelligence (AI) models continues to rise, there is a growing need to develop smaller, more efficient models that can be deployed on resource-constrained devices. While reducing the size of an AI model can help in improving deployment and inference times, maintaining comparable test results is crucial to ensure the model’s accuracy and reliability. In this article, we will explore four effective techniques — model distillation, model pruning, model quantization, and dataset distillation — that enable the creation of compact AI models without compromising performance.
Model Distillation:
In machine learning, knowledge distillation is the process of transferring knowledge from a large model to a smaller one. While large models have higher knowledge capacity than small models, this capacity might not be fully utilized. Knowledge distillation transfers knowledge from a large model to a smaller model without loss of validity. [1]
Model distillation involves training a smaller student model to mimic the behavior of a larger, more complex teacher model. By leveraging the knowledge learned by the teacher model, the student model can achieve comparable performance while having a significantly reduced size. This process typically involves training the student model using a combination of the original training data and the soft labels produced by the teacher model. By distilling the knowledge from the teacher model into the student model, we can create a compact model that retains the essential information necessary for accurate predictions.

Model Pruning:
Model pruning is a technique that involves removing unnecessary connections, parameters, or entire layers from a pre-trained neural network. Pruning can be done based on various criteria, such as weight magnitude, sensitivity analysis, or structured sparsity. By eliminating redundant or less important components, we can significantly reduce the model’s size while preserving its performance. Furthermore, pruning can also lead to improved inference speed and reduced memory requirements, making it an attractive approach for deploying AI models on resource-constrained devices.

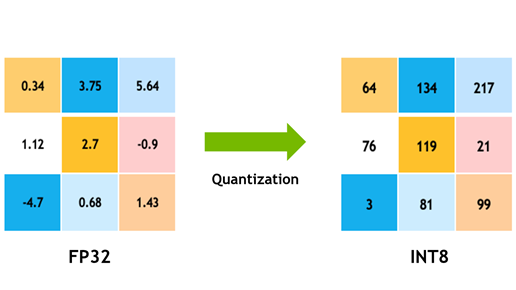
Model Quantization:
Model quantization is the process of reducing the precision of numerical values in a neural network. Typically, deep learning models use 32-bit floating-point numbers (FP32) to represent weights and activations. However, by quantizing the model to lower bit-width representations, such as 8-bit integers (INT8), we can substantially reduce the model size and memory footprint.
Reducing the number of bits means the resulting model requires less memory storage, consumes less energy (in theory), and operations like matrix multiplication can be performed much faster with integer arithmetic. It also allows to run models on embedded devices, which sometimes only support integer data types.
Although quantization may introduce some quantization errors, modern techniques like quantization-aware training can minimize the loss of accuracy. With proper calibration and optimization, quantized models can achieve performance similar to their full-precision counterparts while requiring less computational resources. You can check this article by NVIDIA to gain more knowledge on quantization-aware training.
In 8-bit quantization, each weight and activation value in the model is constrained to an 8-bit integer, which can represent values from 0 to 255. This means that instead of using a wide range of floating-point values, we limit the range to a discrete set of integer values. This reduction in precision allows for efficient storage and computation, as 8-bit integers require fewer bits than 32-bit floating-point numbers.
It’s worth noting that 8-bit quantization is just one example of quantization. There are other quantization techniques, such as 4-bit quantization, which further reduces the precision to 4-bit integers. The main idea remains the same — representing weights and activations with fewer bits to achieve smaller model sizes and lower memory requirements.
For more in-depth information on quantization, including different techniques and implementation details, you can refer to the article “Quantization” in the Hugging Face documentation. The article provides a comprehensive guide to understanding and implementing quantization in AI models. You can access it at the following link: Hugging Face — Quantization
Dataset Distillation:
In addition to compressing the model, another approach to reducing AI model size is dataset distillation. The idea behind this technique is to train a smaller model using a curated subset of the original training data. By selecting representative samples that cover the data distribution, we can create a distilled dataset that captures the key patterns and characteristics of the full dataset. Training the model on this distilled dataset allows us to achieve comparable performance while significantly reducing the storage requirements for training and deploying the model.

Conclusion:
Efficiency and compactness are essential considerations when deploying AI models in resource-limited environments. By employing techniques like model distillation, model pruning, model quantization, and dataset distillation, we can effectively reduce the size of AI models without sacrificing their performance. These techniques provide practical solutions for optimizing model size, enabling deployment on edge devices, mobile platforms, and other resource-constrained environments. As AI continues to advance, striking the right balance between model size and performance will play a vital role in driving the widespread adoption of AI technologies across various domains.
More Stories
What is Machine UnLearning and how can it help with Ethical AI? 🤔
[1] https://en.wikipedia.org/wiki/Knowledge_distillation